This domain makes up 24% of the exam and includes the following 4 objectives:
1. Identify elastic and scalable compute solutions for a workload
2. Select high-performing and scalable storage solutions for a workload
3. Select high-performing networking solutions for a workload
4. Choose high-performing database solutions for a workload
5. Be able to select the best storage and database services to use for a given scenario, taking into account requirements for performance.
know how to effectively implement elasticity and scalability to your application architectures.
Task Statement 1: Determine high-performing and/or scalable storage solutions.
Knowledge of:
• Hybrid storage solutions to meet business requirements
• Storage services with appropriate use cases (for example, Amazon S3, Amazon Elastic File System [Amazon EFS], Amazon Elastic Block Store [Amazon EBS])
• Storage types with associated characteristics (for example, object, file, block)
Skills in:
• Determining storage services and configurations that meet performance demands
• Determining storage services that can scale to accommodate future needs
Task Statement 2: Design high-performing and elastic compute solutions.
Knowledge of:
• AWS compute services with appropriate use cases (for example, AWS Batch, Amazon EMR, Fargate)
• Distributed computing concepts supported by AWS global infrastructure and edge services
• Queuing and messaging concepts (for example, publish/subscribe)
• Scalability capabilities with appropriate use cases (for example, Amazon EC2 Auto Scaling, AWS Auto Scaling)
• Serverless technologies and patterns (for example, Lambda, Fargate)
• The orchestration of containers (for example, Amazon ECS, Amazon EKS)
Skills in:
• Decoupling workloads so that components can scale independently
• Identifying metrics and conditions to perform scaling actions
• Selecting the appropriate compute options and features (for example, EC2 instance types) to
meet business requirements
• Selecting the appropriate resource type and size (for example, the amount of Lambda memory) to meet business requirements Task Statement 3: Determine high-performing database solutions.
Knowledge of:
• AWS global infrastructure (for example, Availability Zones, AWS Regions)
• Caching strategies and services (for example, Amazon ElastiCache)
• Data access patterns (for example, read-intensive compared with write-intensive)
• Database capacity planning (for example, capacity units, instance types, Provisioned IOPS)
• Database connections and proxies
• Database engines with appropriate use cases (for example, heterogeneous migrations, homogeneous migrations)
• Database replication (for example, read replicas)
• Database types and services (for example, serverless, relational compared with non-relational, in-memory)
Skills in:
• Configuring read replicas to meet business requirements
• Designing database architectures
• Determining an appropriate database engine (for example, MySQL compared with
PostgreSQL)
• Determining an appropriate database type (for example, Amazon Aurora, Amazon DynamoDB)
• Integrating caching to meet business Task Statement 4: Determine high-performing and/or scalable network architectures.
Knowledge of:
• Edge networking services with appropriate use cases (for example, Amazon CloudFront, AWS Global Accelerator)
• How to design network architecture (for example, subnet tiers, routing, IP addressing)
• Load balancing concepts (for example, Application Load Balancer)
• Network connection options (for example, AWS VPN, Direct Connect, AWS PrivateLink)
Skills in:
• Creating a network topology for various architectures (for example, global, hybrid, multi-tier)
• Determining network configurations that can scale to accommodate future needs
• Determining the appropriate placement of resources to meet business requirements
• Selecting the appropriate load balancing strategy
Task Statement 5: Determine high-performing data ingestion and transformation solutions.
Knowledge of:
• Data analytics and visualization services with appropriate use cases (for example, Amazon Athena, AWS Lake Formation, Amazon QuickSight)
• Data ingestion patterns (for example, frequency)
• Data transfer services with appropriate use cases (for example, AWS DataSync, AWS Storage Gateway)
• Data transformation services with appropriate use cases (for example, AWS Glue)
• Secure access to ingestion access points
• Sizes and speeds needed to meet business requirements
• Streaming data services with appropriate use cases (for example, Amazon Kinesis)
Skills in:
• Building and securing data lakes
• Designing data streaming architectures
• Designing data transfer solutions
• Implementing visualization strategies
• Selecting appropriate compute options for data processing (for example, Amazon EMR)
• Selecting appropriate configurations for ingestion
• Transforming data between formats (for example, .csv to .parquet)
0
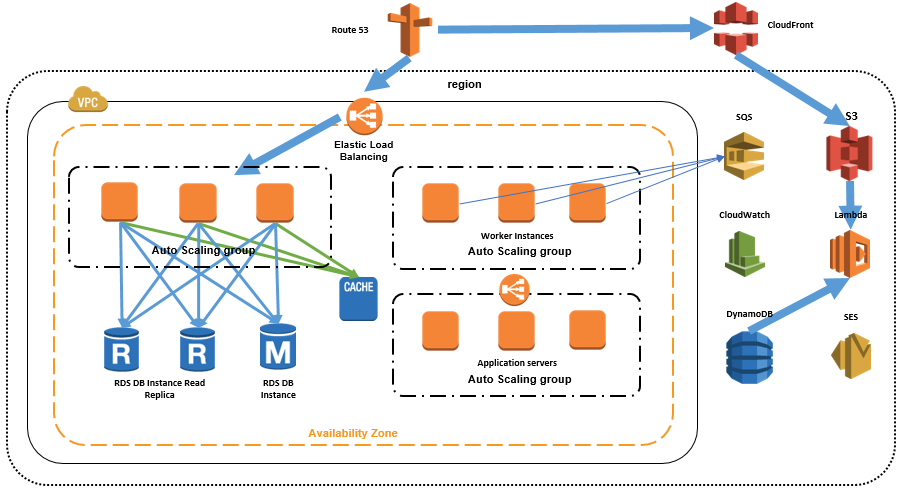
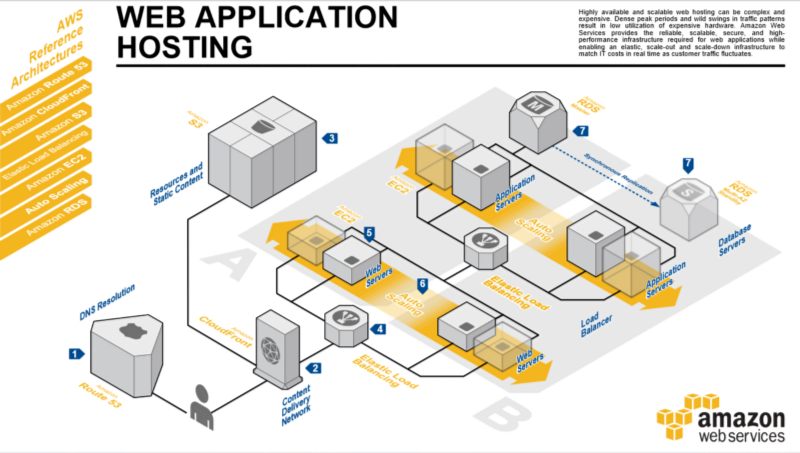
CloudFront vs Global Accelerator
Both CloudFront and Global Accelerator can speed up the distribution of contents over the AWS global network. AWS Global Accelerator works at the network layer and is able to direct traffic to optimal endpoints. CloudFront delivers content through edge locations and users are routed to the edge location that has the lowest time delay.
1
Multipart Upload in SDK
Because with byte-range fetches, users can establish concurrent connections to Amazon S3 to fetch different parts from within the same object. Through the "Range" header in the HTTP GET request, a specified portion of the objects can be downloaded instead of the whole objects.
2
S3 Lifecycle configuration
Lifecycle configuration allows lifecycle management of objects in a bucket. The configuration is a set of one or more rules, where each rule defines an action for Amazon S3 to apply to a group of objects. Bucket policies and IAM define access to objects in an S3 bucket. CORS enables clients in one domain to interact with resources in a different domain.
3
Target Tracking Scaling Policy
A target tracking scaling policy can be applied to check the ASGAverageCPUUtilization metric. In ASG, you can add a target tracking scaling policy based on a target
4
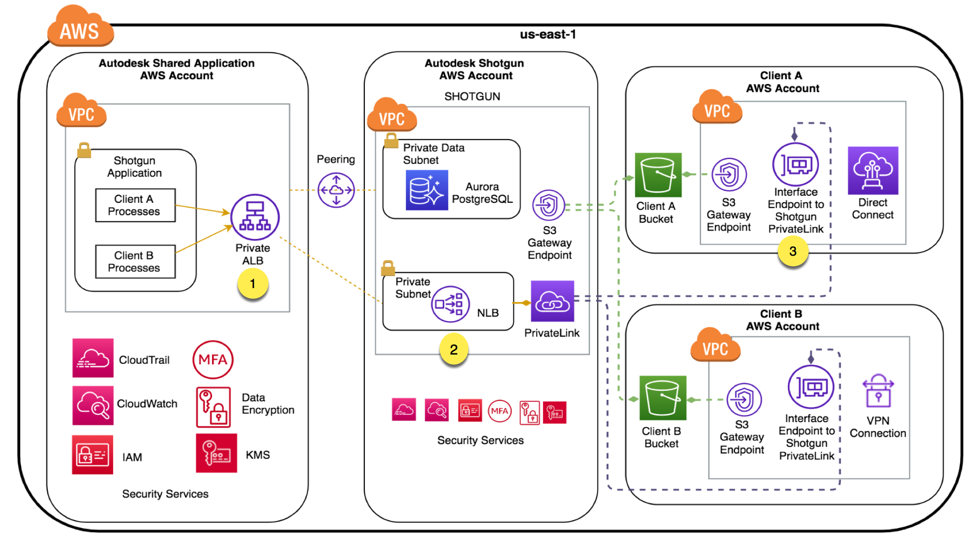
AWS Direct Connect
AWS Direct Connect can reduce network costs, increase bandwidth throughput, and provide a more consistent network experience than internet-based connections. It uses industry-standard 802.1q VLANs to connect to Amazon VPC using private IP addresses. You can choose from an ecosystem of WAN service providers for integrating your AWS Direct Connect endpoint in an AWS Direct Connect location with your remote networks. AWS Direct Connect lets you establish 1 Gbps or 10 Gbps dedicated network connections (or multiple connections) between AWS networks and one of the AWS Direct Connect locations. You can also work with your provider to create sub-1G connection or use link aggregation group (LAG) to aggregate multiple 1 gigabit or 10 gigabit connections at a single AWS Direct Connect endpoint, allowing you to treat them as a single, managed connection. A Direct Connect gateway is a globally available resource to enable connections to multiple Amazon VPCs across different regions or AWS accounts.
5
Placement Groups
Amazon Web Services' (AWS) solution to reducing latency between instances involves the use of placement groups. As the name implies, a placement group is just that -- a group. AWS instances that exist within a common availability zone can be grouped into a placement group. Group members are able to communicate with one another in a way that provides low latency and high throughput. A cluster placement group is a logical grouping of instances within a single Availability Zone. A cluster placement group can span peered VPCs in the same Region. Instances in the same cluster placement group enjoy a higher per-flow throughput limit of up to 10 Gbps for TCP/IP traffic and are placed in the same high-bisection bandwidth segment of the network.
Placement groups are a clustering of EC2 instances in one Availability Zone with fast (up to 25Gbps) connections between them. This feature is used for applications that need extremely low-latency connections between instances.
6
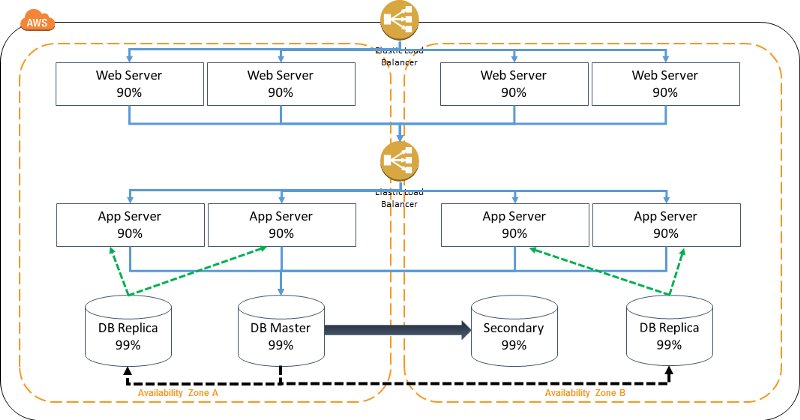
Appication Load Balancer vs Classic Load Balancer
Only the Application Load Balancer can support path-based and host-based routing. Using an Application Load Balancer instead of a Classic Load Balancer has the following benefits:
- Support for path-based routing. You can configure rules for your listener that forward requests based on the URL in the request. This enables you to structure your application as smaller services, and route requests to the correct service based on the content of the URL.
- Support for host-based routing. You can configure rules for your listener that forward requests based on the host field in the HTTP header. This enables you to route requests to multiple domains using a single load balancer.
- Support for routing based on fields in the request, such as standard and custom HTTP headers and methods, query parameters, and source IP addresses.
Using an Application Load Balancer instead of a Classic Load Balancer has the following benefits: Support for path-based routing. You can configure rules for your listener that forward requests based on the URL in the request. This enables you to structure your application as smaller services, and route requests to the correct service based on the content of the URL.
7
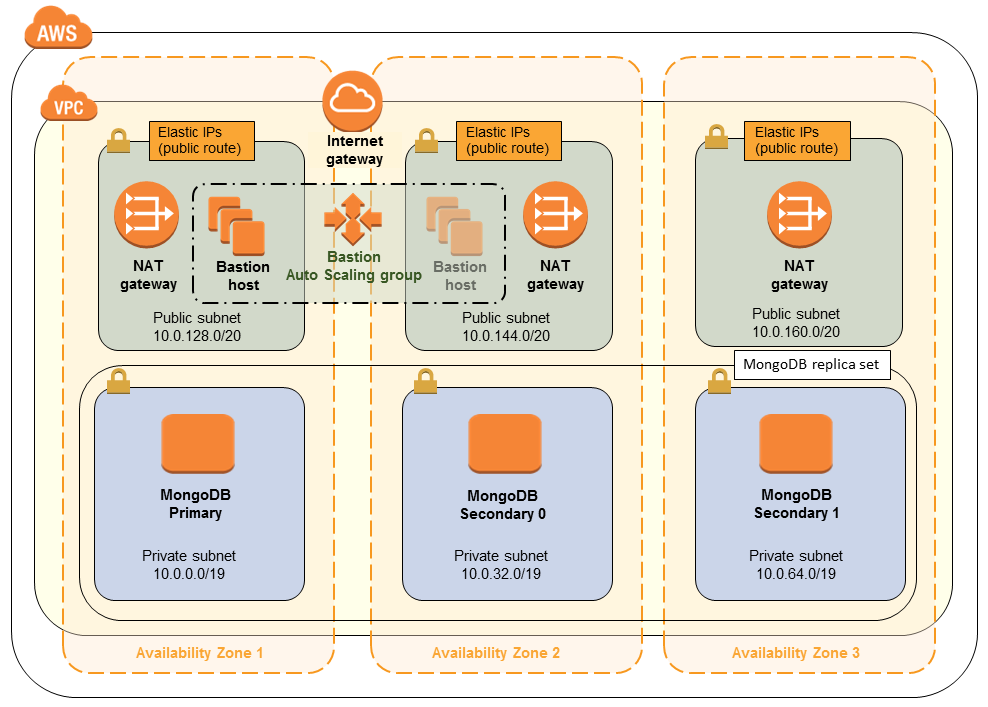
Disaster Recovery: Read Replicas
Amazon RDS Read Replicas for MySQL and MariaDB now support Multi-AZ deployments. Combining Read Replicas with Multi-AZ enables you to build a resilient disaster recovery strategy and simplify your database engine upgrade process. Amazon RDS Read Replicas enable you to create one or more read-only copies of your database instance within the same AWS Region or in a different AWS Region. Updates made to the source database are then asynchronously copied to your Read Replicas. In addition to providing scalability for read-heavy workloads, Read Replicas can be promoted to become a standalone database instance when needed.
8
Gaming: Kinesis Data Streams
Kinesis Data Streams can be used to continuously collect data about player-game interactions and feed the data into your gaming platform. With Kinesis Data Streams, you can design a game that provides engaging and dynamic experiences based on players’ actions and behaviors.
9
Predictive Scaling Policy
Use a predictive scaling policy on the Auto Scaling Group to meet opening and closing spikes: Using data collected from your actual EC2 usage and further informed by billions of data points drawn from our own observations, we use well-trained Machine Learning models to predict your expected traffic (and EC2 usage) including daily and weekly patterns. The model needs at least one day’s of historical data to start making predictions; it is re-evaluated every 24 hours to create a forecast for the next 48 hours. What we can gather from the question is that the spikes at the beginning and end of day can potentially affect performance. Sure, we can use dynamic scaling, but remember, scaling up takes a little bit of time. We have the information to be proactive, use predictive scaling, and be ready for these spikes at opening and closing.
10
Amazon DynamoDB auto scaling
Amazon DynamoDB auto scaling uses the AWS Application Auto Scaling service to dynamically adjust provisioned throughput capacity on your behalf, in response to actual traffic patterns. This enables a table or a global secondary index to increase its provisioned read and write capacity to handle sudden increases in traffic, without throttling. When the workload decreases, Application Auto Scaling decreases the throughput so that you don't pay for unused provisioned capacity. Note that if you use the AWS Management Console to create a table or a global secondary index, DynamoDB auto scaling is enabled by default. You can modify your auto scaling settings at any time.
11
How can you improve the performance of EFS?
Amazon EFS now allows you to instantly provision the throughput required for your applications independent of the amount of data stored in your file system. This allows you to optimize throughput for your application’s performance needs.
12
Stateful vs Stateless web Services
- A stateful web service will keep track of the "state" of a client's connection and data over several requests. So for example, the client might login, select a users account data, update their address, attach a photo, and change the status flag, then disconnect.
In a stateless web service, the server doesn't keep any information from one request to the next. The client needs to do it's work in a series of simple transactions, and the client has to keep track of what happens between requests. So in the above example, the client needs to do each operation separately: connect and update the address, disconnect. Connect and attach the photo, disconnect. Connect and change the status flag, disconnect.
A stateless web service is much simpler to implement, and can handle greater volume of clients.
13
An Edge Location is a specialization AWS data centre that works with which services?
Lambda@Edge lets you run Lambda functions to customize the content that CloudFront delivers, executing the functions in AWS locations closer to the viewer.
Amazon CloudFront is a web service that speeds up distribution of your static and dynamic web content, such as .html, .css, .js, and image files, to your users. CloudFront delivers your content through a worldwide network of data centers called edge locations. When a user requests content that you're serving with CloudFront, the user is routed to the edge location that provides the lowest latency (time delay), so that content is delivered with the best possible performance.
CloudFront speeds up the distribution of your content by routing each user request through the AWS backbone network to the edge location that can best serve your content. Typically, this is a CloudFront edge server that provides the fastest delivery to the viewer. Using the AWS network dramatically reduces the number of networks that your users' requests must pass through, which improves performance. Users get lower latency—the time it takes to load the first byte of the file—and higher data transfer rates.
You also get increased reliability and availability because copies of your files (also known as objects) are now held (or cached) in multiple edge locations around the world.
14
A software gaming company has produced an online racing game which uses CloudFront for fast delivery to worldwide users. The game also uses DynamoDB for storing in-game and historical user data. The DynamoDB table has a preconfigured read and write capacity. Users have been reporting slow down issues, and an analysis has revealed that the DynamoDB table has begun throttling during peak traffic times. Which step can you take to improve game performance?
Make sure DynamoDB Auto Scaling is turned on.
Amazon DynamoDB auto scaling uses the AWS Application Auto Scaling service to dynamically adjust provisioned throughput capacity on your behalf, in response to actual traffic patterns. This enables a table or a global secondary index to increase its provisioned read and write capacity to handle sudden increases in traffic, without throttling. When the workload decreases, Application Auto Scaling decreases the throughput so that you don't pay for unused provisioned capacity. Note that if you use the AWS Management Console to create a table or a global secondary index, DynamoDB auto scaling is enabled by default. You can modify your auto scaling settings at any time.
15
You have configured an Auto Scaling Group of EC2 instances. You have begun testing the scaling of the Auto Scaling Group using a stress tool to force the CPU utilization metric being used to force scale out actions. The stress tool is also being manipulated by removing stress to force a scale in. But you notice that these actions are only taking place in five-minute intervals. What is happening?
The Auto Scaling Group is following the default cooldown procedure.
- The cooldown period helps you prevent your Auto Scaling group from launching or terminating additional instances before the effects of previous activities are visible. You can configure the length of time based on your instance startup time or other application needs. When you use simple scaling, after the Auto Scaling group scales using a simple scaling policy, it waits for a cooldown period to complete before any further scaling activities due to simple scaling policies can start. An adequate cooldown period helps to prevent the initiation of an additional scaling activity based on stale metrics. By default, all simple scaling policies use the default cooldown period associated with your Auto Scaling Group, but you can configure a different cooldown period for certain policies, as described in the following sections. Note that Amazon EC2 Auto Scaling honors cooldown periods when using simple scaling policies, but not when using other scaling policies or scheduled scaling. A default cooldown period automatically applies to any scaling activities for simple scaling policies, and you can optionally request to have it apply to your manual scaling activities. When you use the AWS Management Console to update an Auto Scaling Group, or when you use the AWS CLI or an AWS SDK to create or update an Auto Scaling Group, you can set the optional default cooldown parameter. If a value for the default cooldown period is not provided, its default value is 300 seconds.